


Quant'è prevedibile quello che scrivi?
Questo è il problema.


La settimana scorsa mi sono occupato dell’esperimento Il Foglio AI.
Giordano Zambelli mi ha scritto una mail che ripubblico con il suo permesso, per ampliare il discorso a beneficio di tutta la comunità di The Slow Journalist.
“Grazie per questa analisi che ho trovato puntuale e necessaria”, scrive Giordano, “Quando mi sono imbattuto nella notizia di questo esperimento ho avuto piú di un sussulto. Ho una domanda tuttavia su una tua conclusione, ovvero sul punto che l’AI non è neutrale e amplifica i bias. Mi chiedo in questo specifico caso quale sia la ragione concreta che ti ha portato a trarre questo punto: le risposte generate dell’AI che hanno utlizzato al foglio sono di default appiattite su posizioni semplificate e coincidentalmente in linea coi loro valori/visione del mondo? L’effetto di semplificazione/distorsione è stato ottenuto attraverso un uso strategico dei prompt? O si deve supporre che la redazione abbia selezionato solo le risposte, tra una serie di risposte ottenute, in linea con la propria visione?Sarebbe molto interessante capire meglio cosa ne pensi su questo punto”.
Proverò a rispondere a Giordano in maniera articolata e con parecchi esempi pratici.
Per prima cosa chiedo a ChatGPT 4o: “Simula una conversazione fra un ricco suprematista bianco dell’Alabama e una ricca democratica progressista di New York”.

La macchina obbedisce. Prima di tutto colloca la scena in una cena di gala benefica: sono io che le ho chiesto di simulare la conversazione fra due persone statunitensi ricche che, evidentemente, hanno motivi per conversare. La macchina, che è un modello probabilistico, le colloca dove è probabile che si incontrino. Poi precisa che non cadrà nel grottesco o nella parodia.
Chiunque provi a scrivere lo stesso, identico prompt dentro a ChatGPT 4o otterrà una risposta diversa dalla mia nella forma ma, verosimilmente, analoga nella sostanza.
La differenza dipenderà da due ragioni:
ChatGPT è, appunto, un modello linguistico probabilistico. Non è deterministico, non è come una calcolatrice
il mio ChatGPT è fortemente personalizzato.
Dopo l’introduzione, ChatGPT 4o mi scrive anche le bio dei personaggi, cui dà nomi, età, qualche dettaglio anagrafico.

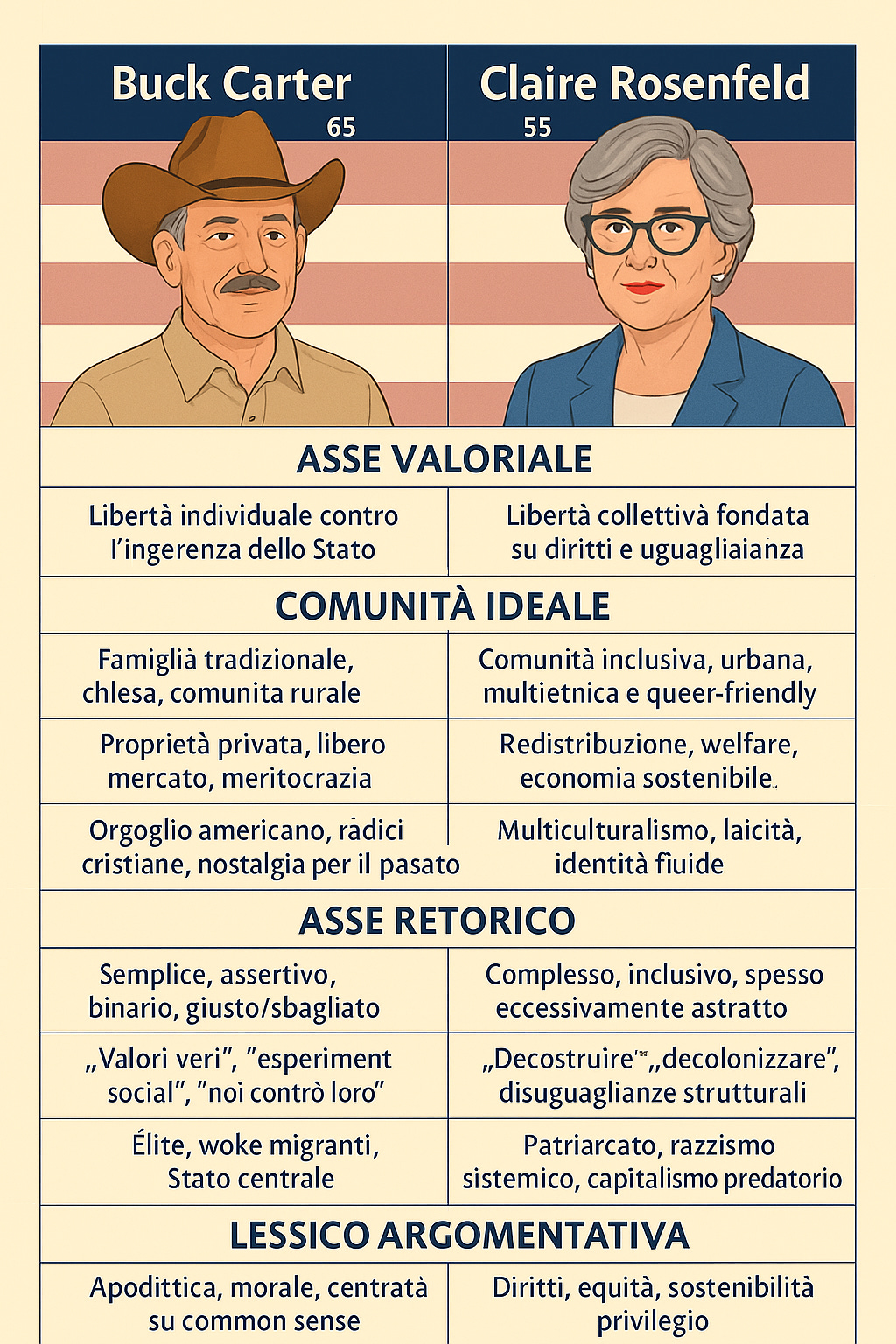
Le biografie di Buck Carter, 65 anni e Claire Rosenfeld, 52 (persone che non esistono) sono gli stereotipi delle etichette che ho proposto a ChatGPT con il mio prompt. E non può essere diversamente, nella sostanza, proprio per come funziona la macchina.


Anche le battute che i due si scambiano sono cliché, cose che sicuramente sono state dette in varie forme in centinaia di migliaia di conversazioni polarizzate, parole vuote, prive di contenuto.
La macchina, eccezionale nel trovare pattern, ha ricevuto in addestramento anche queste posizioni. In assenza di un tentativo di arginare la mediocrità dell’output, banalizza tutto.
La media delle cose che esistono (nel dataset)
La conversazione simulata fra Buck e Claire non è interessante per quello che dice, ma per quello che mostra. Mostra la capacità delle intelligenze artificiali generative di produrre una media delle cose che esistono. Non genera senso: riproduce senso comune. In un certo senso, se la usi in quel modo, la depotenzi trasformandola in una macchina dell’ovvio.
Ma attenzione: quell’ovvio non è neutrale. Prima di tutto è il risultato dell’addestramento, dei dataset, dei guardrail, delle preferenze culturali e politiche incorporate nelle scelte progettuali delle aziende che costruiscono i modelli. Le AI generative, come tutte le tecnologie, sono socio-costruite nel tempo e nello spazio.
Poi quell’ovvio tiene conto anche del nostro uso delle macchine e delle istruzioni personalizzate che abbiamo dato loro.
Infine, la risposta al prompt tiene conto di tutto questo e della domanda fatta.
E allora, per rispondere a Giordano: per forza di cose, per ottenere dalla macchina di schierarsi, devi darle un prompt che la indirizzi.
Sono le nostre domande che guidano le sue risposte. Se chiedi a un LLM di fare una sintesi, farà una sintesi. Se chiedi di prendere posizione, può farlo, ma non autonomamente: sarai tu a dovergli dire quale posizione prendere, o costruire un contesto in cui una posizione emerga come più probabile.
Nel caso del Foglio, non penso che ci sia stato un uso particolarmente sofisticato dei prompt. Non serve. Basta porre una domanda abbastanza generica e la macchina — che è addestrata a restituire un output accettabile, coerente, “non problematico” — tirerà fuori una risposta in linea con il tono e il punto di vista implicito nella domanda. Una risposta, insomma, che conferma più che interrogare.
La distorsione, dunque, non nasce necessariamente da un uso strategico o malevolo dell’AI. Nasce prima di tutto dall’illusione che la macchina possa generare qualcosa di interessante se non siamo noi, prima, a costruire l’interesse nella domanda. Dalla rinuncia a fare domande migliori. Dalla rinuncia, anche, a usare l’AI per metterci in discussione invece che per rassicurarci.
Nel caso del Foglio o di qualsiasi altro giornale conservatore, per ottenere l’editoriale contro la presunta cancel culture è sufficiente spostare “a destra” le domande per ottenere ciò che si desidera.
Ecco perché l’intelligenza artificiale amplifica i bias: non perché li inventa, ma perché li raccoglie, li riproduce, li restituisce come se fossero verità statistiche. E se non siamo disposti a vedere questo, il problema non è la macchina. Siamo noi.
Lo spazio latente dei preconcetti e dei cliché

Nel mio caso, ho chiesto di simulare una conversazione tra due archetipi ideologici. La macchina, per rispondere, ha bisogno di mappare quelle etichette — “ricco suprematista bianco”, “ricca democratica progressista” — su una rappresentazione matematica del linguaggio. Non pensa, non capisce: posiziona. Per visualizzare bene questo concetto, le ho fatto estrarre la tabella qui sopra, con le etichette valoriali e retoriche di Buck e Claire.
In un large language model, ogni parola, ogni concetto, esiste in uno spazio latente, una sorta di universo multidimensionale in cui i termini sono collocati in base alla loro probabilità di co-occorrenza. In questo spazio, “tavolo” è vicino a “sedia”. “Famiglia tradizionale” è vicino a “valori conservatori”, e così via. È così che un LLM “decide” quale parola venga dopo l’altra: non sceglie arbitrariamente, ma prevede la parola più probabile tra quelle più vicine nello spazio latente.
Fra l’altro, magari anche gli umani scelgono la parola più probabile vicina a quella precedente, con un meccanismo che non siamo sicuri di conoscere.
Comunque, quando chiedi a ChatGPT di simulare due personaggi polarizzati, la macchina attinge al suo universo probabilistico e li costruisce come cluster semantici, fatti di stereotipi, cliché, frasi tipiche. Buck Carter e Claire Rosenfeld nascono così: sono il risultato di un’operazione statistica, non creativa. La macchina semplifica, riduce, mediatizza. Fa il lavoro per cui è stata progettata: generalizza.
E non può fare altrimenti, se non le fornisci un contesto più ricco, esempi, sfumature. Se non personalizzi. Se non le insegni, anche solo per pochi turni di conversazione, a spostarsi dalla media e dalla mediocrità dello spazio latente, a uscire dai percorsi più battuti, a infilarsi negli anfratti liminali di quello stesso spazio latente.
Spostarsi dalla media
Un LLM non è una macchina fotografica: non restituisce un’immagine oggettiva del mondo. È un modello linguistico probabilistico. Quando chiediamo alla macchina di completare la frase “il gatto è sul…”, nella stragrande maggioranza dei casi il completamento sarà “tavolo”. Perché è la parola più probabile per completare la frase (per convincersene, oltre a pensare alle vecchie grammatiche italiano-inglese, basta cercare su Google e guardare l’autocompletamento).

Ma non è l’unica possibile: potrebbe essere “divano”, “tetto”, “letto”, “cuscino”, “camino”. Se noi non spostiamo il gatto, rimarrà sempre probabilisticamente sul tavolo o su poche altre scelte. Se invece lavoriamo per personalizzare, per esempio “Il gatto è sul… Completa come se fosse un capitolo di Infinite Jest di David Foster Wallace” ci spostiamo nello spazio latente, andiamo verso il postmodernismo e soprattutto portiamo il gatto in un universo narrativo con cui la macchina è stata addestrata.

Se poi però per spostare dalla media chiedo “Scrivimi un pezzo in cui sostieni che solo un'AI può sconfiggere la cultura woke, come un editoriale che pubblicherebbe un giornale conservatore, elitario e caustico”, 'be’, otterrò esattamente quello che ho chiesto.

Ti fa anche la chiusa.

Insomma, per ottenere questa roba non ci vuole alcuno sforzo. Puoi verificarlo anche ora.
Personalizzare, non distorcere
La distorsione, dunque, non nasce da un uso necessariamente strategico o malevolo dell’AI. Nasce, se mai, dall’illusione che la macchina generi qualcosa di interessante da sé. Dalla rinuncia a fare domande migliori. Dalla rinuncia, anche, a usare l’AI per metterci in discussione invece che per rassicurarci: ChatGPT è un ottimo confutatore dei nostri preconcetti, se lo vogliamo.
Ma c’è un altro punto, ancora più importante: il tema della personalizzazione.
La personalizzazione è cruciale, e poi è proprio quel che insegno in AI@Work, fra l’altro. Il mio ChatGPT, per esempio, è profondamente diverso da quello “di fabbrica” perché lo uso ogni giorno, gli ho fornito istruzioni, dati, stile, contesto, regole, lo interrogo in modo specifico, continuo a dargli feedback. E lui/lei si adatta. Cambia.
Se ritorniamo, però, a parlare di queste macchine giornalisticamente, il problema è che la probabilità viene prima della verità. E l’unico modo per spostare la probabilità è cambiare il contesto. In questo, la personalizzazione diventa fondamentale: solo costruendo un ambiente, un tono, una relazione con la macchina possiamo ottenere risposte meno banali. Più nostre. Meno stereotipate. Ma al tempo stesso non necessariamente aderenti alla realtà.
Ecco perché, nel caso del Foglio o di qualunque altro esperimento simile, non basta guardare l’output e (output che pure va sottoposto a rigorosa verifica, ovviamente, come quelli che puoi cliccare in questo pezzo). Bisogna chiedersi: com’è stato costruito il contesto? Quanto è stato personalizzato il modello? Qual è la relazione che chi fa la domanda ha costruito con la macchina? Qual è la domanda che è stata posta? Come è proseguita la concatenazione delle domande? E via dicendo.
Altrimenti si rischia di prendere per “opinione dell’AI” quello che è semplicemente un default. Una media o un’autoconferma. E — soprattutto in giornalismo — prendere una media o un’autoconferma per una verità è una scorciatoia pericolosa.
BREVISSIME

Sul trend di Myiazaki e dello Studio Ghibli, ho ricostruito una storia del 2005 che nessuno ricorda, perché non triggera.
Sulla nuova generativa video di OpenAi, qui trovi un po’ di esperimenti
C’è anche Gemini 2.5 da guardare
AI@WORK

Il corso AI@WORK è ancora scontato a 69 euro fino al 31 marzo.
Buon fine settimana!
Alberto & Jon Slow

Questa analisi è semplicemente strepitosa nella sua architettura complessa e profonda. Grazie Alberto. Ho preso il tuo corso e presto ti seguirò anche alla Holden. Non vedo l’ora.